Two Engines, One Platform
一个平台,两条价值链路
从「我的发明新不新」到「我的专利卖给谁」,NovaScan 把专利情报的两个高频场景做进同一套 Agent + 检索基座。
主战场 · V2
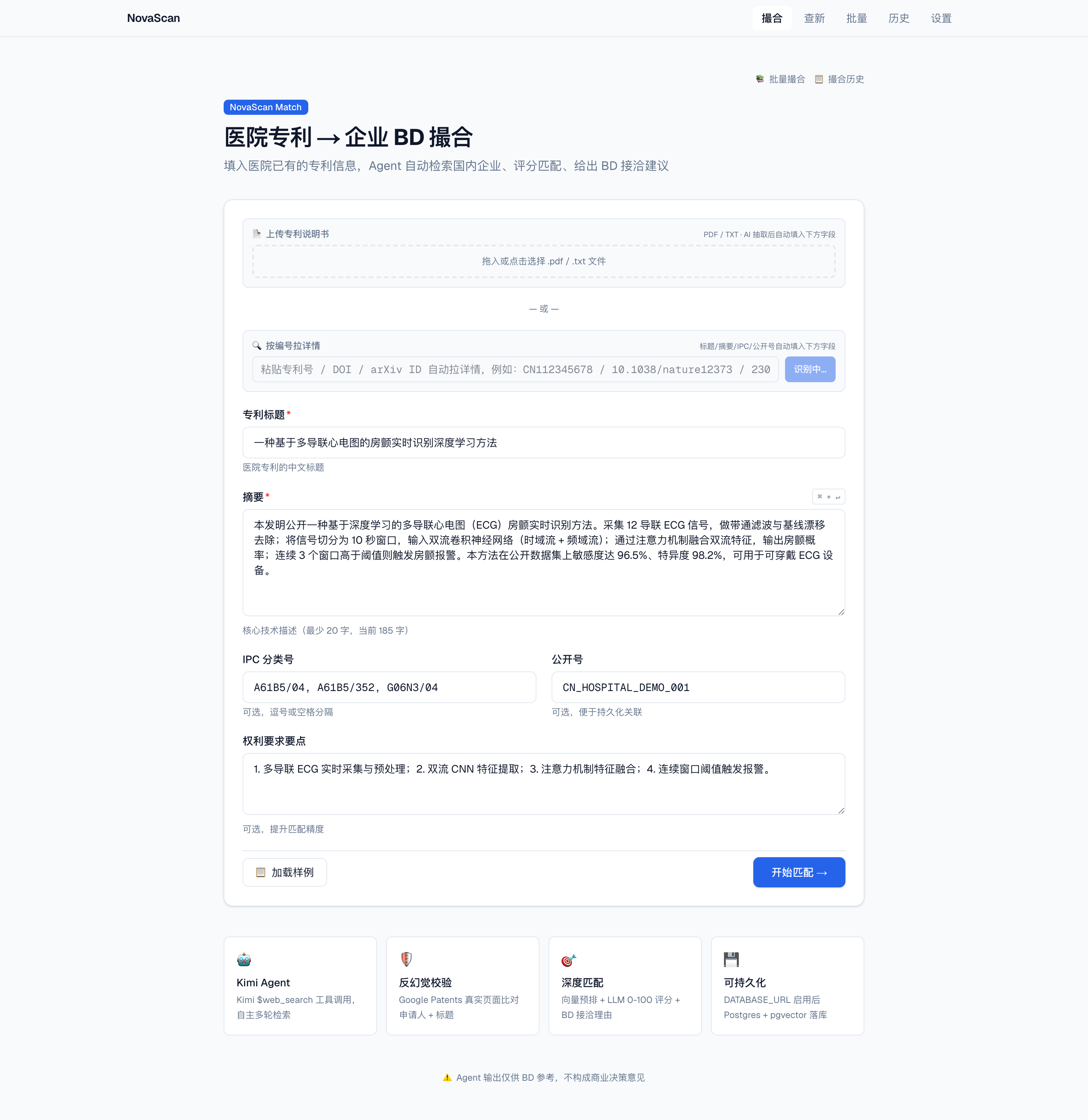
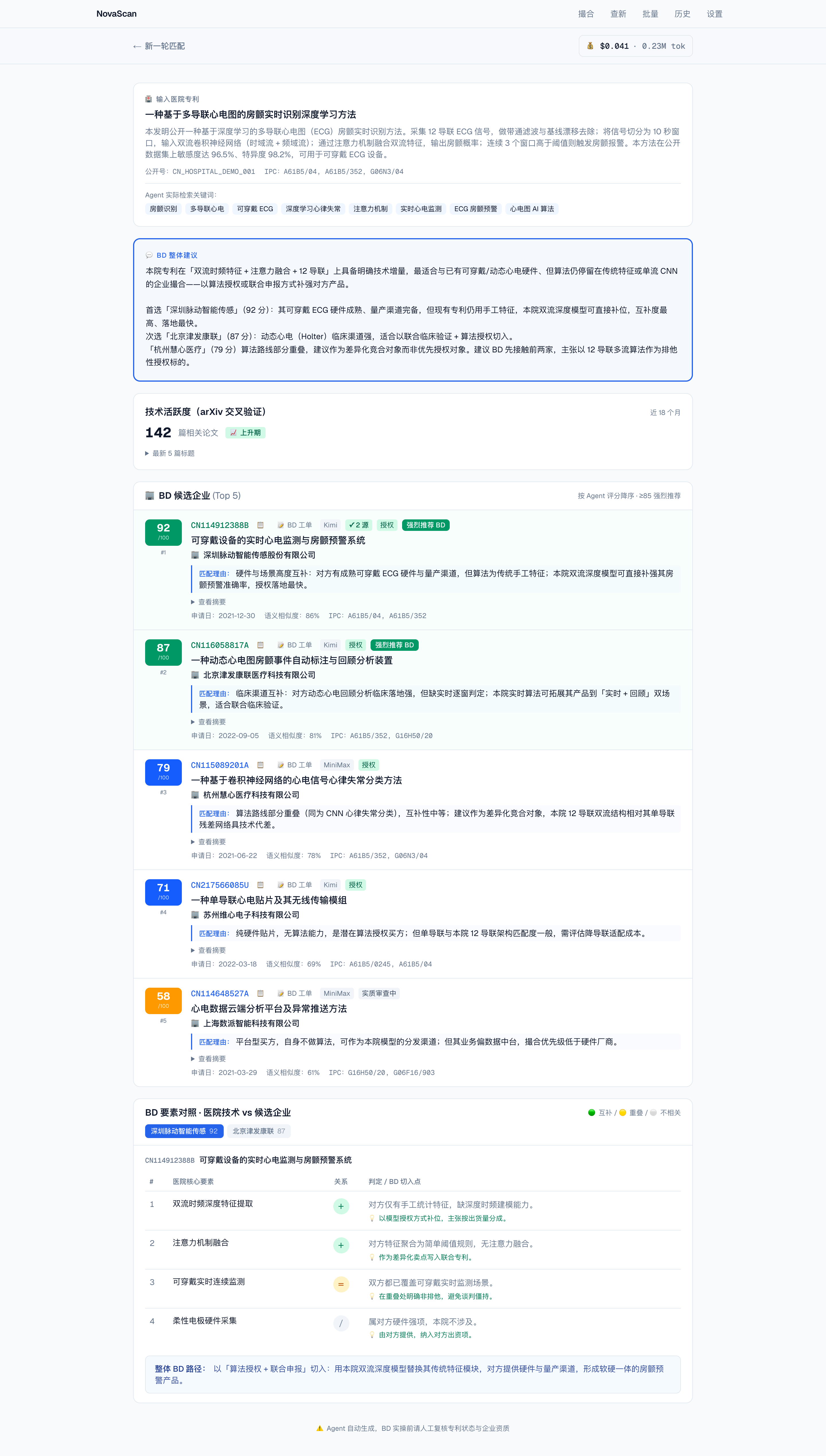
🏥 NovaScan Match
输入医院已有专利,Agent 自动检索国内企业专利、0–100 评分排序,并产出 BD 接洽建议与要素对照。
Kimi 联网 Agent + Google Patents 反幻觉
向量预排 + LLM 深度匹配评分
BD 要素对照(互补 / 重叠)+ 接洽工单
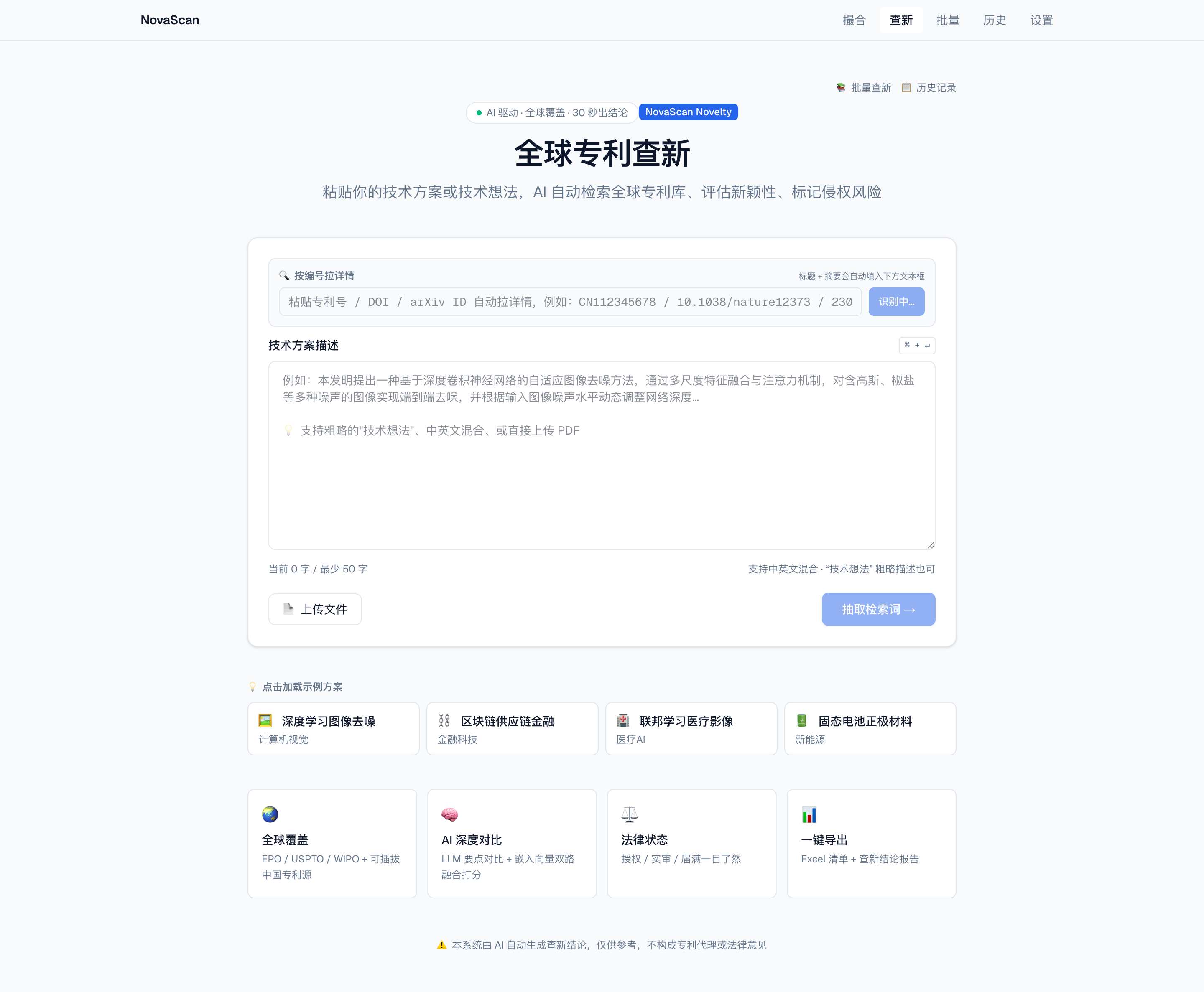
查新引擎 · V1
🔍 NovaScan Novelty
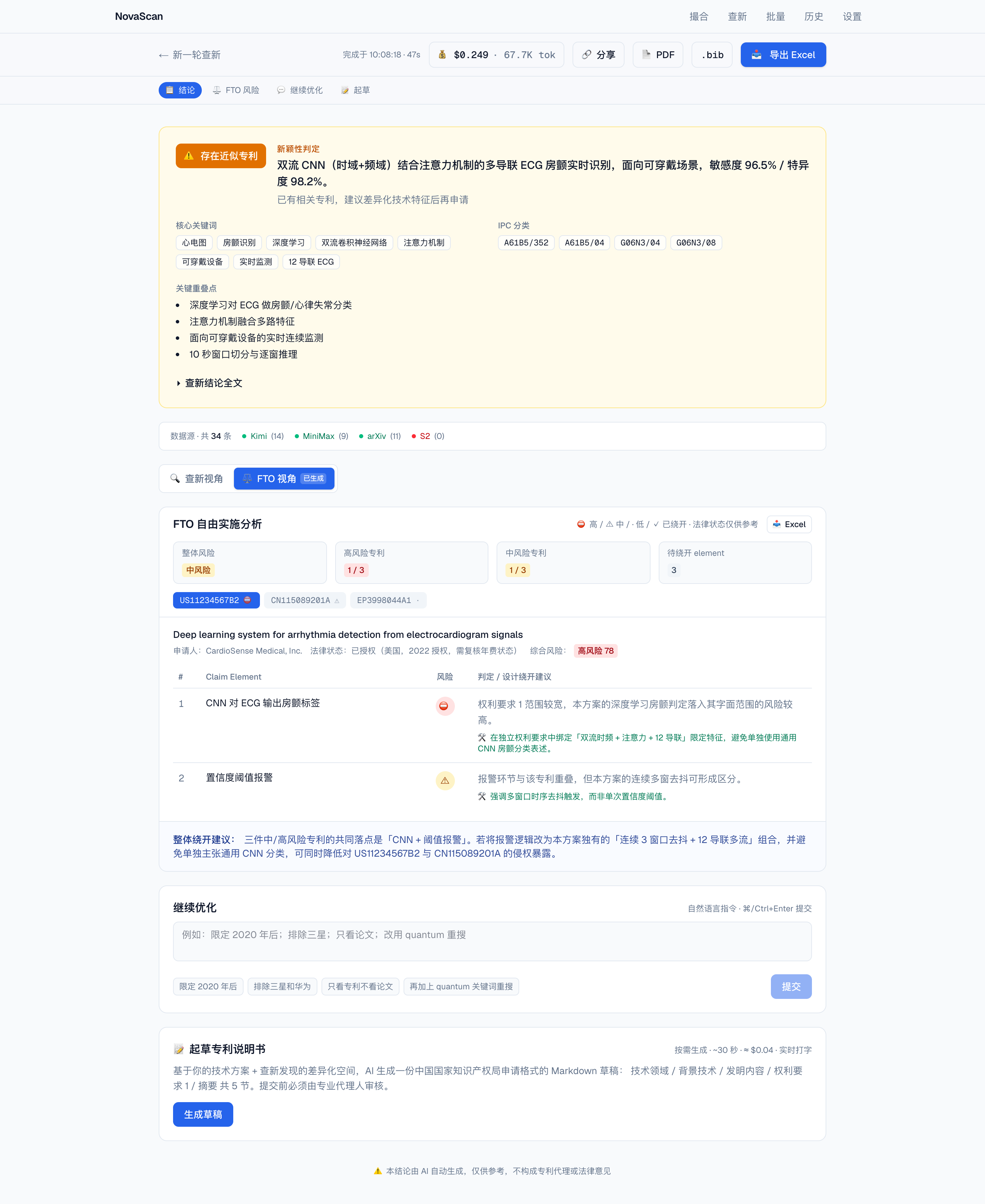
粘贴技术方案,多源实时联网检索评估新颖性,含全球专利 + 学术论文 + 临床试验交叉查证、Claim Chart 与 FTO 双视角。
专利 + 论文 + 临床试验 + 网络多源并行
嵌入相似度排序 + Claim Chart
查新 / FTO 双视角 + Excel·PDF 导出

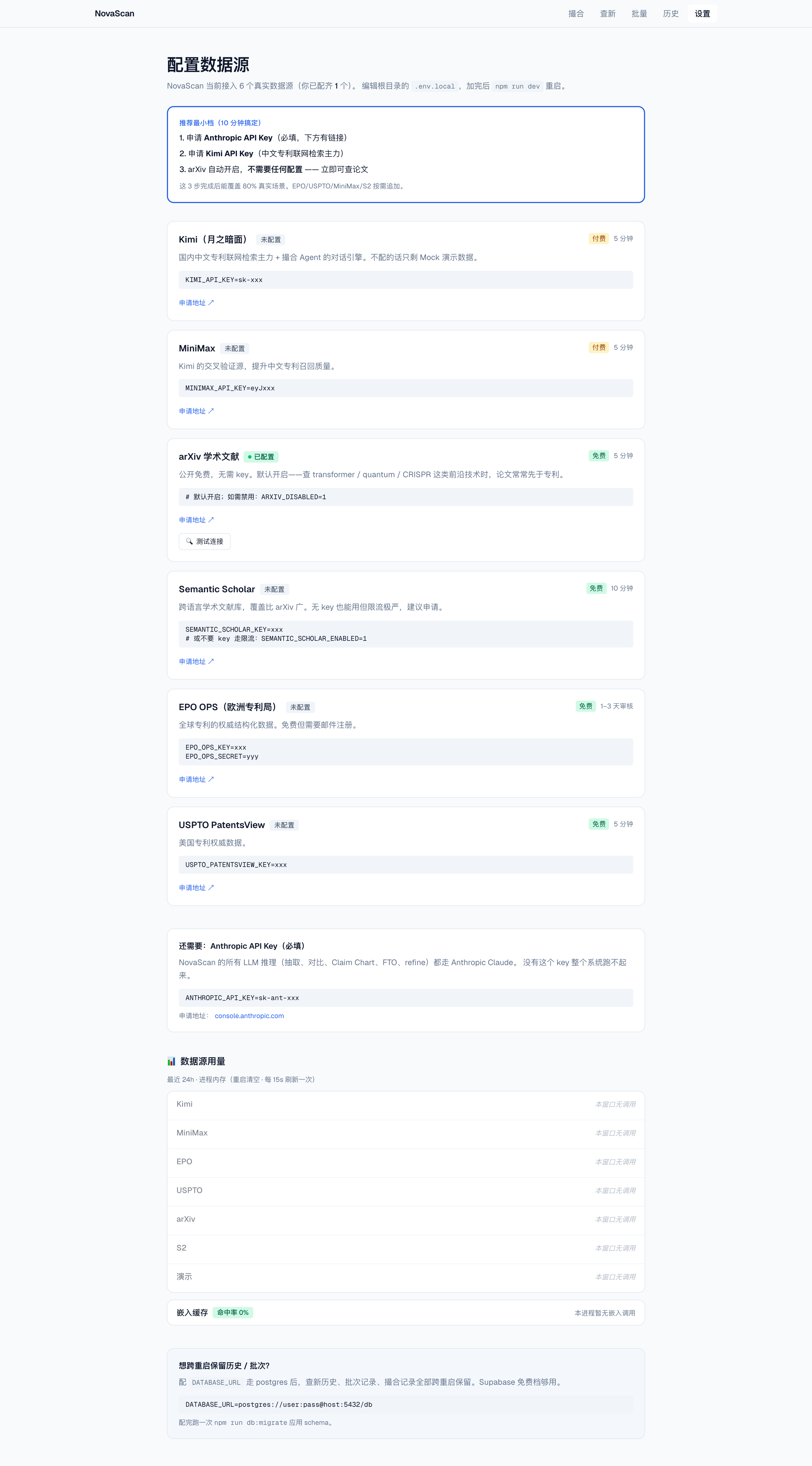
▲ 首页:双引擎入口、近期活动与实时数据源状态一览(点击放大)